Paper presentation
[Paper] Semi-Supervised Classification and Segmentation on High Resolution Aerial Images
Solving the FloodNet problem
In this story, Semi-Supervised Classification and Segmentation on High Resolution Aerial Images, by the authors: Sahil Khose, Abhiraj Tiwari and Ankita Ghosh, is presented. In this paper:
- We analyze the FloodNet dataset for the first time as it was released as a part of the EARTHVISION 2021 workshop (hosted by CVPR) in March 2021 and we were one of the teams who participated in it.
- Solve the problem of scarcity of labelled data for the binary classification problem using pseudo label generation. Beating the best model of the FloodNet paper by 3% with less than half the number of parameters.
- Analyze the results of various multi-class semantic segmentation models with varying backbones over 10 classes and compare them when we introduce our semi-supervised approach from classification.
This paper is submitted to CVPR 2021 under the EARTHVISION 2021 workshop.
Outline:
- What is FloodNet?
- Flooded vs Non-Flooded — Semi-Supervised Classification
- 10 class semantic segmentation
- Conclusion
1. What is FloodNet?
- FloodNet is a high-resolution image dataset acquired by a small UAV platform, DJI Mavic Pro quadcopters, after Hurricane Harvey.
- These high resolution (3000x4000x3) images are accompanied by detailed semantic annotation regarding the damages.
- To advance the damage assessment process for post-disaster scenarios, the dataset provides a unique challenge considering classification, semantic segmentation and visual question answering.
The FloodNet competition under EARTHVISION 2021 has 2 tracks:
- Track 1: Image Classification and Semantic Segmentation,
- Track 2: Visual Question Answering.
We worked on Track 1 of the competition and submitted the paper on the same.
Dataset Details
- The whole dataset has 2343 images, divided into training (~60%), validation (~20%) and test (~20%) sets.
- For Track 1 (Semi-Supervised Classification and Semantic Segmentation), in the training set, we have around 400 labeled images (~25% of the training set) and around 1050 unlabeled images (~75% of the training set).
- For Track 2 (Supervised VQA), in the training set, we have around 1450 images with a total of 4511 image-question pairs.
Track 1
In this track, there are two semi-supervised tasks:
- Semi-Supervised Classification: Classification for FloodNet dataset requires classifying the images into ‘Flooded’ and ‘Non-Flooded’ classes. Only a few of the training images have their labels available, while most of the training images are unlabeled.
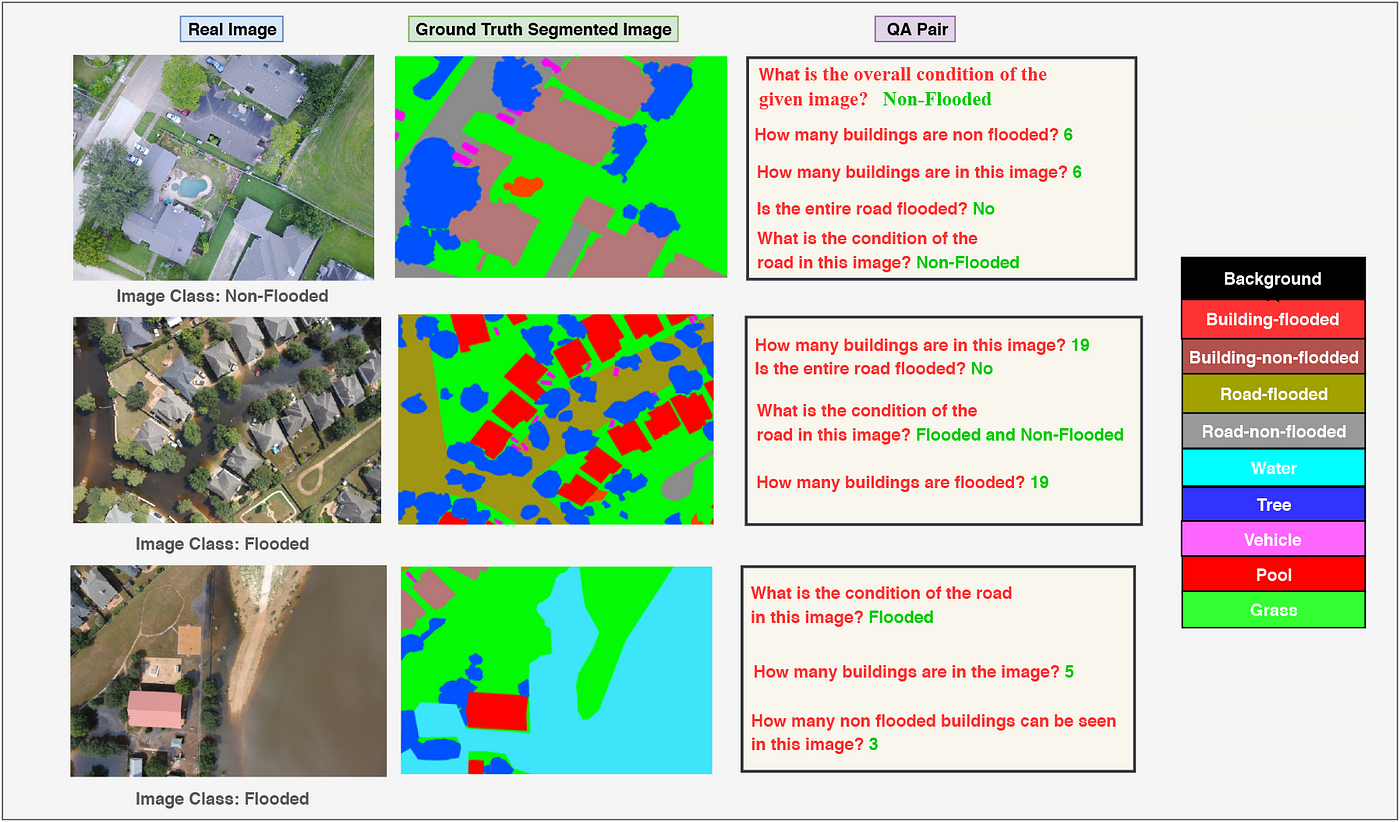
- Semi-Supervised Semantic Segmentation: The semantic segmentation labels include: 1) Background, 2) Building Flooded, 3) Building Non-Flooded, 4) Road Flooded, 5) Road Non-Flooded, 6) Water, 7) Tree, 8) Vehicle, 9) Pool, 10) Grass.
The dataset for Track 1 can be downloaded from this link
Track 2
For the Visual Question Answering (VQA) task there are images associated with multiple questions. The questions are divided into the following categories:
- Simple Counting: Questions will be designed to count the number of objects regardless of their attribute. For example: “how many buildings are there in the image?”.
- Complex Counting: Questions will be asked to count the number of objects belonging to a specific attribute. For example: “how many flooded buildings are there in the image?”.
- Condition Recognition: In this category, all the questions are mainly designed to ask questions regarding the condition of the object and the neighborhood. For example: “What is the condition of the road in the given image?”.
- Yes/No: For this type of question, the answer will be either a ‘Yes’ or a ‘No’. For example: “Is there any flooded road?”.
The dataset for Track 2 can be downloaded from this link
2. Flooded vs Non-Flooded — Semi-Supervised Classification
Data and Preprocessing
- In the given dataset 398 sample images were labeled out of which 51 samples were flooded and 347 were non-flooded.
- The large class imbalance prevents the model from achieving a good F1 score while training with the labeled dataset.
- To prevent this we used a weighted sampling strategy while loading the data in the model. Both the classes were sampled equally during batch generation.
- The labeled dataset was heavily augmented to get more images for training the model under supervision.
- The image samples were randomly cropped, shifted, resized and flipped along the horizontal and vertical axes.
- We downsized the image from 3000×4000 to 300×400 dimensions to strike a balance between processing efficiency gained by the lower dimensional images and information retrieval of the high-resolution images.
Methodology
- ResNet18 with a binary classification head was used for semi-supervised training on the dataset.
- The model was trained for E epochs out of which only the labeled samples were used for Eα_i epochs after which pseudo labels were used to further train the model. α has an initial value of α_i that increases up to α_f from epoch Eα_i to Eα_f as described in Algorithm 1.
- A modified form of Binary Cross-Entropy (BCE) was used as the loss function as shown in line 10 in Algorithm 1 where l is the label of a sample, l_hat is the predicted class for labeled sample and u_epoch is the predicted class for an unlabeled sample in the current epoch. This loss function was optimized using Stochastic Gradient Descent (SGD)

Experiments
- We used ResNet18 as it is computationally efficient. We experimented with Adam optimizer and SGD. Optimizing using SGD was much more stable and the optimizer was less susceptible to overshooting.
- Different values of α were experimented with and it was found that a slow and gradual increase in alpha was better for training the model.
- Our best performing model uses α_i= 0 and α_f= 1. The value of α increases from epoch Eα_i= 10 to Eα_f= 135. The model was trained on a batch size of 64.
Results
- Our system performed significantly better than all the classification baseline results mentioned in the FloodNet paper while having a considerably smaller architecture (half the number of parameters) as shown in Table 1.
- Our best model achieves 98.10% F1 and 96.70% accuracy on the test set.

3. 10 class semantic segmentation
Data and Preprocessing
- To expedite the process of feature extraction for the deep learning model, we apply a bilateral filter to the image, followed by two iterations of dilation and one iteration of erosion.
- For image augmentation we perform shuffling, rotation, scaling, shifting and brightness contrast.
- The images and masks are resized to 512×512 dimensions while training since high-resolution images preserve useful information.
Methodology
- The dataset contains labeled masks of dimension 3000×4000×3 with pixel values ranging from 0 to 9, each denoting a particular semantic label.
- These are one-hot encoded to generate labels with 10 channels, where i_th channel contains information about i_th class.
- We experiment with various encoder-decoder and pyramid pooling based architectures to train our model, the details of which are mentioned in the Experiments section.
- The loss function used is a weighted combination of Binary Cross-Entropy loss (BCE) and Dice loss as it provides visually cleaner results.
- We apply a semi-supervised approach and generate pseudo masks for the unlabeled images.
- While training the model for E epochs, the labeled samples were used for Eα_i epochs where Adam is used as an optimizer.
- After that pseudo masks were used to further train the model as described in Algorithm 1. α has an initial value of α_i that increases up to α_f from epoch Eα_i to Eα_f.
- SGD optimizer with 0.01 LR is used when pseudo masks are introduced to the model.
Experiments
- We apply three state-of-the-art semantic segmentation models on the FloodNet dataset.
- We adopt one encoder-decoder based network named UNet, one pyramid pooling module-based network PSPNet and the last network model DeepLabV3+ employs both encoder-decoder and pyramid pooling based module.
- We train all of them in a supervised fashion. For UNet, PSPNet and DeepLabV3+ the back-bones used were ResNet34, ResNet101 and EfficientNet-B3 respectively.
- For UNet the learning rate was 0.01 with step LR scheduler set at intervals [10,30,50] and decay factor γ set to 0.1.
- For PSPNet the learning rate was 0.001 without any LR decay. For DeepLabV3+ the learning rate was 0.001 with step LR scheduler set at intervals [7,20] and γ set to 0.1.
- Adam optimizer and batch size of 24 was used for all the models with Mean Intersection over Union (MIoU) as the evaluation metric.
- We observed the best results when we weighed the BCE loss and Dice loss equally.
- Once we recognized the best performing model on the task, we trained a DeepLabV3+ model with EfficientNet-B3 as the backbone and used SGD optimizer instead of Adam optimizer in a semi-supervised fashion.
- Due to computation and memory constraints, we randomly sampled unlabeled data with the ratio of 1:10 for generating the pseudo masks.
Results
- Table 2 showcases the comparison of the best models we achieved for each of the 3 architectures.
- The best test set result was achieved by a DeepLabV3+ architecture with an EfficientNet-B3 backbone.
- A few example images of the predictions of the model against the ground truth are provided in Figure 1.
- It is evident from the table that small objects like vehicles and pools are the most difficult tasks for our models.


To look at all our semantic segmentation maps like the one in Figure 1 checkout our demo
4. Conclusion
- In this work, we have explored methods to approach semi-supervised classification and segmentation along with handling the class imbalance problem on high-resolution images.
- We have conducted a range of experiments to obtain the best possible technique and models to optimize for the tasks.
- Our classification framework achieves laudable results with just 398 labeled images and also utilizes the entirety of the unlabeled data.
- Our segmentation framework shows an increase of 0.19% on using the unlabeled data as pseudo labels. This provides a wide scope of improvement.
- The amount of unlabeled data is approximately three times the amount of labeled data which if employed efficiently can produce superior results. We foresee multiple opportunities for future research.
- Training the model in an unsupervised fashion and fine-tuning it with the labeled data followed by distillation as presented in SimCLRv2 is a very promising method.
- Training with a contrastive loss has been incremental at times. With the emergence of Visual Transformers, self-supervised Vision Transformers could also be explored for this task.
Links
- Semi-Supervised Classification and Segmentation on High Resolution Aerial Images (our paper)
- Semantic Segmentation Outputs Demo
- GitHub repository for our paper’s implementation
- YouTube video of the authors explaining the work
About Author
I am a senior CS undergraduate with a keen interest in Deep Learning. I try to write blogs and I make explanation videos on my YouTube channel where I explain niche and trending deep learning papers every week. I am also open to research collaborations, you can find my details on my website.
